Raspberry Pi Picoで組込みRust開発(開発環境構築編)
先日の出張の際に、秋葉原の千石電商でRaspberry Pi Pico(以下「Pico」)が550円で販売されているのを見つけて、思わず買ってしまいました。Picoは公式にはC/C++とMicro Pythonでの開発に対応していますが、プロセッサのRP2040はArm Cortex-M0+プロセッサなので、組込みRust開発ができそうです。調べてみると、既に対応するクレートが開発されており、英語の導入記事がいくつか見つかりました。以前から組込みRust開発に関心があったので、これらを参考にしてまずクロス開発環境の構築から試してみました。
開発環境構築の前に:はんだ付け
Picoは以下の写真のようにピンヘッダが実装されていない状態で販売されています。

(「Raspberry Pi Pico datasheet」より引用)
通常はブレッドボードに挿して開発するでしょうから、まずピンヘッダをはんだ付けする必要があります。ピンの太さについて、1〜20ピンおよび21〜40ピン(上の写真の横方向に20個ずつ並ぶピン)ではブレッドボードに挿せるように細ピンを、デバッグ用のピン(上の写真の左端、縦方向の3つのピン)では通常の太さを選択します。例えば秋月電子あたりで以下の部品を購入し、内側の穴に挿入してはんだ付けします。
| 部品名 | メーカー | 品番 | 数量 | 備考 |
|---|---|---|---|---|
| 細ピンヘッダ 1×20 | Useconn Electronics Ltd. | PHA-1x20SG | 2 | |
| ピンヘッダ 1×40(40P) | Useconn Electronics Ltd. | PH-1x40SG | 1 | 3ピン分をカットして使用 |
はんだ付けが難しい場合、価格は少々高くなりますが、スイッチサイエンスからピンヘッダ実装済みのPicoが販売されているので、それを購入するのもよいでしょう。
ピンヘッダのはんだ付けが完了したら、ブレッドボードに挿入します。PCとUSBケーブルで接続するので、ケーブルが出る方の端に配置すると、残りの部分に部品を置きやすくなります。

それでは、以下より開発環境を構築していきます。
実行環境
Macでの手順を記述しますが、Linuxでも同様に実行できると思います。
開発に必要なツールの準備
まず、Rustのツールチェインをはじめとした、開発に必要なツールをインストールします。
Rustツールチェインの準備
https://rustup.rs/ の手順に従い、Rustのツールチェインを準備します。インストール済みの場合は rustup update で更新しておきます。その後、rustup、rustc、cargo といったコマンドを実行できることを確認します。
$ rustup --version rustup 1.24.3 (ce5817a94 2021-05-31) info: This is the version for the rustup toolchain manager, not the rustc compiler. info: The currently active `rustc` version is `rustc 1.57.0 (f1edd0429 2021-11-29)` $ rustc --version rustc 1.57.0 (f1edd0429 2021-11-29) $ cargo --version cargo 1.57.0 (b2e52d7ca 2021-10-21)
コンパイルターゲットおよびツールの準備
続いて、プログラムのビルドや転送に必要な、コンパイルターゲットおよびツールをインストールします。
$ rustup target install thumbv6m-none-eabi $ cargo install flip-link elf2uf2-rs
rustup target install は、指定されたコンパイルターゲットに関連するツールチェインをインストールします。thumbv6m-none-eabi は、Cortex-M0+等を含むターゲットトリプル(「プロセッサアーキテクチャ-OS-ABI」という形式のターゲットプラットフォーム表記)です。none がOSなしを示します。
flip-linkは、組込みプログラム実行時のスタックオーバーフローを防止するため、リンク時にメモリ配置を変更するツールです。
elf2uf2-rsは、ビルドしたプログラムをUF2というPicoに書き込める形式に変換するツールです。また、接続されたPicoを自動で探してプログラムを書き込む機能もあります。
LED点滅(Lチカ)プログラムの開発
開発に必要なツールを用意できたので、ようやく組込みプログラムを開発できます。ここでは定番のLED点滅(Lチカ)プログラムを開発してみましょう。
プロジェクトテンプレートの利用
組込みRust開発では、複数種類のクレート(マイクロアーキテクチャクレート、ペリフェラルアクセスクレート、HALクレート、ボードクレート)を利用します。Pico用としては、ペリフェラルアクセスクレート以下の開発が進められています(GitHub: rp-rs)。Pico用のクレートを使用するプロジェクトテンプレート(GitHub: rp-rs/rp2040-project-template)が用意されていますので、これを基に開発すると便利です。また、このテンプレートにはPico基板上のLEDを1秒間隔で点滅(500 ms点灯、500 ms消灯)させるプログラムが含まれています。今回はこれを利用してLチカプログラムを開発します。
プロジェクトテンプレートを利用する際には、cargo-generateが便利です。cargo-generateは、プロジェクトテンプレートのダウンロードおよびプロジェクト用のディレクトリ作成を自動で行ってくれます。まずはこれをインストールします。
$ cargo install cargo-generate
cargo-generateをインストールできたら、実行してプロジェクトを作成します。オプション --git と --branch でGitリポジトリおよびブランチを指定します。また、オプション --name でプロジェクト名を指定します。今回はプロジェクト名を pico-blink としてみました。
# 以下、$HOME: ホームディレクトリ、$WORK_DIR: 作業用ディレクトリ # 作業用ディレクトリに戻る $ popd # プロジェクトを作成する $ cargo generate \ --git https://github.com/rp-rs/rp2040-project-template \ --branch main \ --name pico-blink ⚠️ Unable to load config file: $HOME/.cargo/cargo-generate.toml 🔧 Generating template ... (中略) 🔧 Moving generated files into: `$WORK_DIR/pico-blink`... ✨ Done! New project created $WORK_DIR/pico-blink
プロジェクトを作成できたら、そのディレクトリに移動します。
$ cd pico-blink
クレートの依存性の修正(必要な場合のみ)
この記事を書いている2021年12月の時点ではPico用のクレートが積極的に更新されており、プロジェクトテンプレートがそれに追従できていない場合があります。例えばボードクレート名が「pico」から「rp-pico」に変更されたときは、テンプレートのままではプロジェクトをビルドできなくなりました(現在は修正済み)。そのような場合は、Cargo.toml の [dependencies] 節や src/main.rs の use 宣言を確認・修正します。
参考:Update dependencies to released versions of crates · rp-rs/rp2040-project-template@b03e3ee
Cargo.toml の変更
Lチカプロジェクト用に Cargo.toml を変更します。特に package.name はビルド時の出力ファイル名にも影響しますので、変えておきましょう。
--- a/Cargo.toml +++ b/Cargo.toml @@ -1,8 +1,8 @@ [package] -authors = ["the rp-rs team"] +authors = ["ocha"] # 自分の名前 edition = "2018" readme = "README.md" -name = "rp2040-project-template" +name = "pico-blink" # プロジェクト名 version = "0.1.0" resolver = "2"
この段階で、Gitのコミットを作成しておきます。
$ git init $ git add -A $ git commit -m "最初のコミット"
プロジェクトのビルド
プロジェクトテンプレートにLチカプログラムが含まれていますので、そのままビルドしてみましょう。次のコマンドでビルドを実行します。
$ cargo build # ELFファイル target/thumbv6m-none-eabi/debug/pico-blink が生成される
ビルドに失敗した場合は、開発ツールが適切にインストールされているか見直します。
プログラムのPicoへの書き込みおよび実行
ビルドが成功したら、プログラムをPicoに書き込んで実行してみましょう。PicoはPCにUSB(コネクタはマイクロB型)で接続すると、USBストレージとして認識されます。このストレージにUF2形式のファイルをコピーすれば、開発したプログラムがPicoに書き込まれます。
PicoをPCに接続する際は、以下に示すBOOTSELボタンを押しながら行います。これは、既にPicoにプログラムが書き込まれている場合、そのまま接続するとそのプログラムが実行されてしまい、プログラムを書き込めないためです。BOOTSELボタンを押しながら接続すると、書き込まれたプログラムは実行されず、新たなプログラムを書き込めるようになります。

BOOTSELボタンを押しながらPicoを接続すると、Macでは「RPI-RP2」という名前のドライブとしてマウントされました。ここにUF2形式のファイルをコピーして書き込みたいところですが、ビルドで生成されたのはELF形式のファイルですので、そのままでは書き込めません。
先ほどインストールしたツールのうち、elf2uf2-rsはELF形式からUF2形式への変換を行います。また、-d というオプションを付けて実行することで、変換後にPicoのドライブへのコピーを自動で行ってくれます。今回はこれをランナーとして指定して実行します。
ランナーは .cargo/config.toml で指定できます。プロジェクトテンプレートには、elf2uf2-rsを使う場合の設定もコメントの形で用意されています。以下のようにコメントの位置を変更して、elf2uf2-rsを指定します。
--- a/.cargo/config.toml +++ b/.cargo/config.toml @@ -2,8 +2,8 @@ # probe-run is recommended if you have a debugger # elf2uf2-rs loads firmware over USB when the rp2040 is in boot mode [target.'cfg(all(target_arch = "arm", target_os = "none"))'] -runner = "probe-run --chip RP2040" -# runner = "elf2uf2-rs -d" +# runner = "probe-run --chip RP2040" +runner = "elf2uf2-rs -d" rustflags = [ "-C", "linker=flip-link",
.cargo/config.toml を変更したら、いよいよプログラムの書き込み・実行です。cargo run を実行します。
$ cargo run
Finished dev [optimized + debuginfo] target(s) in 0.04s
Running `elf2uf2-rs -d target/thumbv6m-none-eabi/debug/pico-blink`
Found pico uf2 disk /Volumes/RPI-RP2
Transfering program to pico
30.00 KB / 30.00 KB [=====================================] 100.00 % 17.19 MB/s
elf2uf2-rsがUF2ファイルをコピーすると、Picoにプログラムが書き込まれ、自動的にマウント解除されます。書き込み後、すぐにプログラムが実行されます。以下のようにPicoの基板上のLEDが点滅すれば成功です。
LEDの点滅を確認できたら、この状態でコミットします。
$ git commit -a -m 'ランナーとしてelf2uf2-rsを使う'
リセットボタンの設置
Picoにプログラムを書き込む際、毎回USBケーブルを抜き挿ししてリセットするのは面倒です。別の手段として、PicoのRUNピン(ピン番号30)をGNDに落としてリセットする方法があります。この方法ならばUSBケーブルの抜き挿しは不要となり、便利です。
PicoのRUNピンを制御するには、押すとGNDに接続されるタクトスイッチを用意するのが手軽です。次の回路図のようにタクトスイッチを接続して、リセットボタンとします。RUNピンはRP2040内部の約50 kΩの抵抗でプルアップされるので、プルアップ抵抗の追加は不要です。
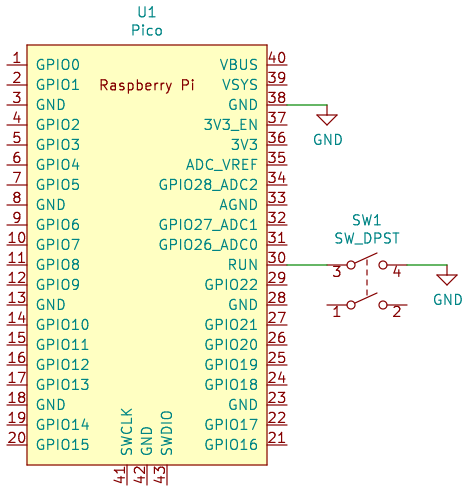
以下はブレッドボードでの接続例です。

接続後、リセットボタンを押してLチカプログラムが再起動することを確認します。また、BOOTSELボタンを押しながらリセットボタンを押すと、PicoのUSBストレージがマウントされてプログラムを書き込めるようになることも確認します。
Lチカプログラムの内容
Lチカプログラムは src/main.rs に記述されています。初期状態のソースコードは以下のとおりです(説明のため、コメントを追加してあります)。内容を見てみましょう。
//! Blinks the LED on a Pico board //! //! This will blink an LED attached to GP25, which is the pin the Pico uses for the on-board LED. // 1. クレートレベルアトリビュート #![no_std] #![no_main] // 2. use宣言 use cortex_m_rt::entry; use defmt::*; use defmt_rtt as _; use embedded_hal::digital::v2::OutputPin; use embedded_time::fixed_point::FixedPoint; use panic_probe as _; // Provide an alias for our BSP so we can switch targets quickly. // Uncomment the BSP you included in Cargo.toml, the rest of the code does not need to change. use rp_pico as bsp; // use pro_micro_rp2040 as bsp; use bsp::hal::{ clocks::{init_clocks_and_plls, Clock}, pac, sio::Sio, watchdog::Watchdog, }; // 3. エントリポイント #[entry] fn main() -> ! { // 4. 変数の準備、初期設定 info!("Program start"); // 4.1. シングルトンパターン let mut pac = pac::Peripherals::take().unwrap(); let core = pac::CorePeripherals::take().unwrap(); let mut watchdog = Watchdog::new(pac.WATCHDOG); let sio = Sio::new(pac.SIO); // 4.2. クロックとPLLの設定 // External high-speed crystal on the pico board is 12Mhz let external_xtal_freq_hz = 12_000_000u32; let clocks = init_clocks_and_plls( external_xtal_freq_hz, pac.XOSC, pac.CLOCKS, pac.PLL_SYS, pac.PLL_USB, &mut pac.RESETS, &mut watchdog, ) .ok() .unwrap(); // 4.3. ビジーウェイトの抽象化 let mut delay = cortex_m::delay::Delay::new(core.SYST, clocks.system_clock.freq().integer()); // 4.4. ピンの集合 let pins = bsp::Pins::new( pac.IO_BANK0, pac.PADS_BANK0, sio.gpio_bank0, &mut pac.RESETS, ); // 4.5. LEDピン let mut led_pin = pins.led.into_push_pull_output(); // 4. ここまで // 5. メインループ loop { info!("on!"); led_pin.set_high().unwrap(); delay.delay_ms(500); info!("off!"); led_pin.set_low().unwrap(); delay.delay_ms(500); } }
1. クレートレベルアトリビュート
クレートレベルアトリビュートとして、#![no_std] および #![no_main] を使用しています。前者は標準ライブラリとして最低限の機能のみ持つcoreクレートを使用することを、後者は通常の main() 関数を使わないことを宣言します。OSを使用しないフリースタンディング環境では、C言語開発でもよく見るような指定です。
2. use 宣言
use 宣言で、よく使う要素を簡潔に書けるようにしています。cortex_m_rtやembedded_halといったCortex-M向け開発で典型的と思われるものに加えて、いくつか見慣れない要素がありました。
defmtは、knurling-rsプロジェクトによる軽量ログ出力フレームワークです。今回は使用していませんが、デバッガ(もう1枚のPicoなど)を接続したときのログ出力で活用できます。panic_probeも、パニック時にデバッガへバックトレースを出力するという点で関連しています。
bsp と別名を付けられている、rp_picoがボードクレートです。コメントで、別名を付けているのはボードクレートを変更しても残りの部分を変更せずに済むようにするためと書かれています。bsp::hal はRP2040のHALクレート(rp2040_hal)、 bsp::hal::pac はRP2040のペリフェラルアクセスクレート(rp2040_pac)です。sio は「Single-cycle IO」の略で、GPIO等に1サイクルでアクセスする機能を提供します。
3. エントリポイント
cortex_m_rt クレートが提供する #[entry] アトリビュートで、最初に実行する関数を指定しています。#![no_main] アトリビュートによって通常の main() 関数を使わないことを宣言したため、これが必要になります。関数名は main でなくても問題ありません。
main() 関数の型 ! はnever型と呼ばれ、値を返さない(return しない)ことを示します。#[entry] アトリビュートがこの型([unsafe] fn() -> !)を要求しています。
4. 変数の準備、初期設定
main() 関数の最初で、変数の準備や初期設定を行っています。let mut pac から let pins までは、お決まりのパターンとなりそうです。
4.1. シングルトンパターン
let mut pac = pac::Peripherals::take().unwrap(); let core = pac::CorePeripherals::take().unwrap();
pac や core で見られる take().unwrap() という部分は、Rustでのシングルトンパターンの書き方です。Rustの所有権システムを利用して、インスタンスがここだけに存在することを保証します。これにより、アクセスの競合が発生しなくなります。
4.2. クロックとPLLの設定
let external_xtal_freq_hz = 12_000_000u32; let clocks = init_clocks_and_plls( external_xtal_freq_hz, pac.XOSC, pac.CLOCKS, pac.PLL_SYS, pac.PLL_USB, &mut pac.RESETS, &mut watchdog, ) .ok() .unwrap();
init_clocks_and_plls 関数では、クロックとPLL(Phase Locked Loop、周波数を逓倍する回路)を初期状態に設定します。Pico基板に実装されている外部クロックの周波数は12 MHzですが、PLLによって125 MHzまで速くなります。また、USB用に48 MHzクロックも生成します。
4.3. ビジーウェイトの抽象化
let mut delay = cortex_m::delay::Delay::new(core.SYST, clocks.system_clock.freq().integer());
delay(cortex_m::delay::Delay)は、Cortex-MのSysTickタイマを利用したビジーウェイトを提供します。後のメインループ内で、500 msの待機に使われています。new 関数の周波数を指定する引数が読みやすくなっていますが、これはembedded_timeクレートが提供する表現のようです。C++のstd::chronoみたいですね。
4.4. ピンの集合
let pins = bsp::Pins::new( pac.IO_BANK0, pac.PADS_BANK0, sio.gpio_bank0, &mut pac.RESETS, );
pins は、その名のとおりピンの集合の構造体です。ボードクレートのおかげで、Picoのデータシートに書かれているピン名をほぼそのまま使えます。
4.5. LEDピン
let mut led_pin = pins.led.into_push_pull_output();
led_pin は、Pico基板上のLEDが接続されているピンを表すインスタンスです。into_push_pull_output() メソッドで、出力ピンとして設定しています。Pico基板上のLEDは正論理となっているので、Hレベルを出力すると点灯し、Lレベルを出力すると消灯します。
5. メインループ
loop { } 内がメインループです。デバッグ出力を除けば、以下のようにおなじみの手順です。
loop { // LEDを点灯させる(Hレベル出力) led_pin.set_high().unwrap(); // 500 ms待機する delay.delay_ms(500); // LEDを消灯させる(Lレベル出力) led_pin.set_low().unwrap(); // 500 ms待機する delay.delay_ms(500); }
出力ピンおよびビジーウェイトが抽象化されているので、とても読みやすいコードになっています。ピンの出力レベル変更(set_high()、set_low())は Result 型を返しますが、クレートが安定していればまず失敗しないでしょうから、unwrap() で Ok を期待しておきます。
LEDの点灯パターンの変更
LチカプログラムのビルドとPicoへの書き込みができたので、今度は動作を変えてみましょう。例えば、LEDの点灯パターンを次のように変更します。
- 以下を3回繰り返す。
- 100 ms点灯させる。
- 100 ms消灯させる。
- 400 ms待機する。
この場合、メインループは次のように書けます。繰り返しには for 式と範囲を使ってみました。RubyやSwiftに近い見た目です。
loop { for _ in 0..3 { // LEDを点灯させる led_pin.set_high().unwrap(); delay.delay_ms(100); // LEDを消灯させる led_pin.set_low().unwrap(); delay.delay_ms(100); } delay.delay_ms(400); }
変更後、cargo run で書き込み、実行すると、以下のようにLEDが点滅します。
LEDの点灯パターンが変わったことを確認できたら、この状態でコミットします。
$ git commit -a -m 'LEDの点灯パターンを変更する'
まとめ・感想
Raspberry Pi Picoで組込みRust開発を行うための環境構築手順をまとめました。開発に必要なツールをインストールした後、Pico用のクレートを利用するプロジェクトテンプレートを使用してLチカプログラムを開発しました。プログラムのPicoへの書き込みおよび実行には elf2uf2-rs を使用しました。プログラム書き込み前のUSBケーブルの抜き挿しを省略するため、RUNピンをGNDに落とすリセットボタンを設置しました。
今回は開発環境構築の段階なので、多少のインストール作業があるのは分かっていましたが、その作業が rustup と cargo でほぼ完結するというのは想像以上に楽でした。また、v1には届いていないものの、開発時に利用するクレートがしっかりと構成されていて、Rustの表現力の高さを感じることができました。次回はPicoに部品を接続して、GPIOで制御することに挑戦してみたいと思います。
参考文献
- Raspberry Pi公式
- Raspberry Pi Trading Ltd: Raspberry Pi Pico datasheet.
- Raspberry Pi Trading Ltd: Getting started with Raspberry Pi Pico.
- Raspberry Pi Trading Ltd: Raspberry Pi Pico Pinout.
- 組込みRust開発
- The Embedded Rust Book
- The Embedonomicon
- 中林智之、井田健太:基礎から学ぶ組込みRust、C&R研究所(2021)。
- リポジトリ
- クレートのドキュメント
- ボードクレート:rp-pico
- HALクレート:rp2040-hal
- ペリフェラルアクセスクレート:rp2040-pac
- cortex-m
- cortex-m-rt
- embedded-hal
- defmt
- panic-probe
- embedded-time
- 記事
- Jim Hodapp: Getting Started with Rust on a Raspberry Pi Pico (Part 1), Relational Technologist (2021-10-25).
Active Supportを使うと Range#=== が遅くなる
IRCログを記録するRailsアプリの開発中、IRCメッセージの解析において、文字が制御文字か判断する必要があった。その際に case-when で文字列の Range とマッチさせる(Range#=== を呼び出す)と、予想外に遅くなった。ruby-profでボトルネックを調べると、ActiveSupport::CompareWithRange#===という見慣れないメソッドが実行されて、時間がかかっているようだった。そこで、通常の Range#=== と実行速度がどのくらい違うか、ベンチマークをとってみた。
ベンチマークのコード
https://github.com/ochaochaocha3/char_range_eq3_benchmark
IRCメッセージの解析では、各文字が制御文字か調べることを行う。そこで、String#each_char の中で ActiveSupport::CompareWithRange#=== または Range#=== を呼び出すプログラムの実行速度を計測することにした。コードは以下のとおり。
# frozen_string_literal: true require 'benchmark_driver' Benchmark.driver do |x| x.prelude <<~RUBY class Range alias old_eq3 === end require 'active_support/core_ext/range/compare_range' r = "\\x00"..."\\x20" # Example from https://modern.ircdocs.horse/formatting.html#examples s = "Rules: Don't spam 5\\x0313,8,6\\x03,7,8, and especially not \\x029\\x02\\x1D!" RUBY x.report 'Default ===', %q! s.each_char { |c| r.old_eq3(c) } ! x.report 'Active Support ===', %q! s.each_char { |c| r === c } ! end
このスクリプトでは、MJITのk0kubunさんが作られたgemのBenchmarkDriverを利用して、オーバーヘッドを少なくしている。繰り返し前に実行される x.prelude において、Active Supportの読み込み前に alias を使用して、通常の Range#=== に old_eq3 という別名をつけておく。2つの x.report が、繰り返し実行される処理。解析対象の文字列は、IRCメッセージの形式の説明に例として載っていたもの。
実行環境
実行結果
実行結果を以下に示す。
$ bundle exec ruby char_range_eq3_benchmark.rb
Warming up --------------------------------------
Default === 55.360k i/s - 58.740k times in 1.061047s (18.06μs/i)
Active Support === 44.636k i/s - 48.455k times in 1.085554s (22.40μs/i)
Calculating -------------------------------------
Default === 55.020k i/s - 166.081k times in 3.018555s (18.18μs/i)
Active Support === 45.137k i/s - 133.908k times in 2.966715s (22.15μs/i)
Comparison:
Default ===: 55020.0 i/s
Active Support ===: 45136.8 i/s - 1.22x slower
「ActiveSupport::CompareWithRange#=== は通常の Range#=== よりも1.22倍遅い」という結果が得られた。alias で別名をつけたメソッドの呼び出しでこの結果なので、Active Supportによって Range#=== が上書きされていないときに === を呼び出したら、もっと速くなるのかもしれない(未確認)。
原因
ActiveSupport::CompareWithRange#=== が遅い原因は、右辺に Range を指定できるように処理が追加されていること。右辺値が Range かどうかで分岐する。今回は String を渡しているので else 節で単に super が呼び出されるだけだが、比較に時間がかかるのだろう。
def ===(value) if value.is_a?(::Range) is_backwards_op = value.exclude_end? ? :>= : :> return false if value.begin && value.end && value.begin.public_send(is_backwards_op, value.end) # 1...10 includes 1..9 but it does not include 1..10. # 1..10 includes 1...11 but it does not include 1...12. operator = exclude_end? && !value.exclude_end? ? :< : :<= value_max = !exclude_end? && value.exclude_end? ? value.max : value.last super(value.first) && (self.end.nil? || value_max.public_send(operator, last)) else super end end
しかし、Ruby 2.6以降では、標準の Range#=== も Range を受け取れるようになっている(Feature #14473)。したがって、この部分は、Ruby 2.5以下でも同じ挙動となるように残されているものと思われる。将来はこの部分が削除されて、実行速度が向上する(標準の Range#=== と同等になる)のかもしれない。
まとめ
Active Supportを使うと Range#=== が遅くなる。原因は、ActiveSupport::CompareWithRange#=== において、右辺に Range を指定できるように処理が追加されているためだった。
BCDice#rollにおいて3番目以降の引数を使用する処理
「どどんとふのダイスボット」ことBCDiceのダイスロール処理(BCDice#roll)には、多くの引数(7個!)がある。この処理を単純化して引数を減らしたかったため、その呼び出し方について調べた。
背景
BCDice#rollの引数、返り値ともに個数が多すぎる。- 引数が多い分、処理が複雑。
- 引数を減らして処理を簡潔にできないか?
BCDice#roll の引数の意味
dice_cnt [Integer]:ダイスの個数dice_max [Integer]:ダイスの面数dice_sort [Integer]:並べ替え。0:ソートしない、1:足し算ダイスでソート有、2:バラバラロール(Bコマンド)でソート有。3:1+2。dice_add [Integer]:BCDice#roll内での振り足しの閾値?dice_ul [String]:成功判定の演算子dice_diff [Integer]:成功判定の目標値dice_re [Integer]:振り足しロールの閾値
(参考)BCDice#roll の返り値の意味
total [Integer]:出目の合計dice_str [String]:出目を並べた文字列numberSpot1 [Integer]:1が出た個数cnt_max [Integer]:最高値の出目の個数n_max [Integer]:出目の最大値cnt_suc [Integer]:成功数rerollCount [Integer]:個数振り足しロールの振り足し数
目的
以上の背景から、「BCDice#roll をどのような場合に多くの引数で呼び出さなければならないか」を把握することを目的として、ソースコードを調査した。通常、ダイスロールでは 2d6 のようにダイスの個数と面数を指定するため、それ以外の要素(dice_sort 以降)を引数で指定する場合、つまり引数を3個以上とする場合を「多くの引数で呼び出している」と定義した。
調査方法
次のコミット時点におけるソースコードを調査の対象とした。
https://github.com/bcdice/BCDice/tree/f1da744aea852e1ef4e6d79ef329b428f4757385
src ディレクトリで以下のコマンドを実行した。その出力から手作業で、BCDice#roll を3引数以上で呼び出している部分を抽出した。
git grep -n -P '\broll\('
結果(要約)
- 4番目以降の引数を使用する場合は非常に少ない。
- バラバラロール(bcdiceCore.rb:1083)
- 個数振り足しロール(dice/RerollDice.rb:61)
- 上方無限ロール(dice/UpperDice.rb:145)
- ゲームシステム固有ダイスボット
- diceBot/DoubleCross.rb(クリティカル(成功判定))
- diceBot/NinjaSlayer.rb(成功判定)→ リファクタリング(PR #84)で使わなくなった
- 4番目の引数
dice_addを使用する(0以外にする)のは、上方無限ロールのみ。 - ゲームシステム固有ダイスボットで3番目以降の引数を使用する場合、ほとんどは3番目の引数
dice_sortを使用するだけ。
考察
- ほとんどの場合、引数は
dice_cnt、dice_max、dice_sortだけで十分。これだけが用意された単純なメソッドを用意することが、改善案として考えられる。 - 4番目以降の引数を使用する場合が非常に少ないため、それらの場合の処理を
BCDice#rollの外に出すと、処理をより単純化できると考えられる。上で述べた単純なメソッドを使用してさらに複雑な処理を行うメソッドを用意するべき。- 特に
dice_addを使用するのは上方無限ロールだけなので、この部分はUpperRollに移動できるはず。
- 特に
dice_sortの指定ミスが散見されるので、見直すべき。
結果(詳細)
bcdiceCore.rb:1083: dice_dat = roll(dice_cnt, dice_max, (@diceBot.sortType & 2), 0, signOfInequality, diff)- バラバラロール
dice/AddDice.rb:298: return @bcdice.roll(dice_wk, dice_max, sortType)- 加算ロール
dice/RerollDice.rb:61: @bcdice.roll(x, n, (@diceBot.sortType & 2), 0, signOfInequality, diff, rerollNumber)- 個数振り足しロール
dice/UpperDice.rb:145: @bcdice.roll(diceCount, diceMax, (@diceBot.sortType & 2), @upper, @signOfInequality, diceDiff)- 上方無限ロール
diceBot/Airgetlamh.rb:81: dice, diceText = roll(rollCount, 10, @sortType)diceBot/Alsetto.rb:77: dice, diceText = roll(rollCount, 6, @sortType)diceBot/Avandner.rb:65: dice, diceText = roll(rollCount, 10, @sortType)- 並び替え
diceBot/BeastBindTrinity.rb:200: _, dice_str, = roll(dice_tc, 6, (sortType & 1))- ダイス数修正、並べ替えせずに出力
diceBot/BlindMythos.rb:140: _, diceText, = roll(diceCount, 6, isSort)- 並び替え
diceBot/DoubleCross.rb:156: dice_dat = roll(dice_cnt, dice_max, (sortType & 2), 0, "", 0, critical)- クリティカル(成功判定)
diceBot/DoubleCross.rb:182: dice_dat = roll(dice_cnt, dice_max, (sortType & 2), 0, "", 0, critical)- クリティカル(成功判定)
diceBot/EmbryoMachine.rb:82: dice_now, dice_str, = roll(2, 10, (sortType & 1))diceBot/GehennaAn.rb:56: diceValue, diceText, = roll(diceCount, 6, (sortType & 1))diceBot/HatsuneMiku.rb:84: _, diceText, = roll(diceCount, 6, isSort)- 並び替え
diceBot/Illusio.rb:53: dice, diceText = roll(diceCount, 6, @sortTye)- 並び替え?(typoしている?)
diceBot/LiveraDoll.rb:81: dice, diceText = roll(diceCount, 6, @sortType)diceBot/MeikyuDays.rb:90: _, dice_str, = roll(dice_c, 6, (sortType & 1))diceBot/MeikyuKingdom.rb:178: _, dice_str, = roll(diceCount, 6, (sortType & 1))diceBot/MonotoneMusium.rb:64: total, dice_str, = roll(2, 6, @sortType && 1)diceBot/MonotoneMusium_Korean.rb:64: total, dice_str, = roll(2, 6, @sortType && 1)diceBot/Nechronica.rb:100: _, dice_str, n1, cnt_max, n_max = roll(dice_n, 10, 1)diceBot/Nechronica_Korean.rb:100: _, dice_str, n1, cnt_max, n_max = roll(dice_n, 10, 1)diceBot/NightWizard.rb:127: dice_n, dice_str, = roll(2, 6, 0)diceBot/NightWizard.rb:173: dice_n, dice_str, = roll(2, 6, 0)- 並び替え
diceBot/NinjaSlayer.rb:110: dice = roll(m[1], 6, 0, 0, '>=', 2)diceBot/NinjaSlayer.rb:130: dice = roll(m[1], 6, 0, 0, '>=', 3)diceBot/NinjaSlayer.rb:149: dice = roll(m[1], 6, 0, 0, '>=', 4)diceBot/NinjaSlayer.rb:168: dice = roll(m[1], 6, 0, 0, '>=', 5)diceBot/NinjaSlayer.rb:187: dice = roll(m[1], 6, 0, 0, '>=', 6)diceBot/NinjaSlayer.rb:206: dice = roll(m[1], 6, 0, 0, '>=', 4)diceBot/NinjaSlayer.rb:226: dice = roll(m[1], 6, 0, 0, '>=', 2)diceBot/NinjaSlayer.rb:245: dice = roll(m[1], 6, 0, 0, '>=', 3)diceBot/NinjaSlayer.rb:264: dice = roll(m[1], 6, 0, 0, '>=', 4)diceBot/NinjaSlayer.rb:283: dice = roll(m[1], 6, 0, 0, '>=', 5)diceBot/NinjaSlayer.rb:302: dice = roll(m[1], 6, 0, 0, '>=', 6)diceBot/NinjaSlayer.rb:321: dice = roll(m[1], 6, 0, 0, '>=', 4)- 成功判定
diceBot/OrgaRain.rb:49: dice, diceText = roll(diceCount, 10, @sortType)- 並び替え
diceBot/Postman.rb:87: dice, diceText = roll(diceCount, 6, @sortTye)diceBot/Raisondetre.rb:79: dice, diceText = roll(rollCount, 10, @sortTye)diceBot/Raisondetre.rb:133: dice, diceText = roll(rollCount, 10, @sortTye)- 並び替え?(typoしている?)
diceBot/SRS.rb:56: total, dice_str, = roll(2, 6, @sortType && 1)- 並び替えだが、値は常に
trueとなる
- 並び替えだが、値は常に
diceBot/Strave.rb:79: dice, diceText = roll(diceCount, 10, @sortType)diceBot/Torg.rb:102: dummy = roll(1, 20, 0)diceBot/TunnelsAndTrolls.rb:165: rollTotal, rollDiceResultText, roll_cnt1, rollDiceMaxCount, roll_n_max, roll_cnt_suc, roll_cnt_re = roll(dice_wk, 6, (sortType & 1))- 並び替え
diceBot/TwilightGunsmoke.rb:76: total, dice_str, = roll(2, 6, @sortType && 1)- 並び替えだが、値は常に
trueとなる
- 並び替えだが、値は常に
MediaWikiのページをStructured Discussionsボードに変換するメンテナンススクリプト
就職して1年ほど経ち毎日忙しいが、スパロボWikiや型月Wikiなどのwikiの管理はなんとか続けている。今後もクリエイターズネットワークのMediaWiki環境は最新の状態に保ち、また積極的に新機能を導入していきたい。
先日、クリエイターズネットワークのwikiで使われているMediaWikiを最新版の1.32.1に更新した。その際、スパロボWiki、型月Wiki、ガンダムWikiにStructured Discussionsという拡張機能を新しく導入した。この拡張機能を個々のページに対して有効化すると、そのページを便利な掲示板として使うことができる。しかし、この拡張機能が提供する移行機能を使用すると、詳細不明のエラーが発生して対象ページの移行作業が中断されてしまう場合があった。このエラーを回避することとエラー発生時に原因を調べやすくすることを目的として、単一のページの移行作業を行うことができるメンテナンススクリプトを作った。
動機
拡張機能Structured Discussionsは、記法が守られなければ無法地帯となりがちであるMediaWikiのトークページに、以下の図のような本格的な掲示板の機能を追加する。

MediaWikiの公式サイトにおいて利用者として使用してみると、
- 投稿者と投稿日時が必ず表示される
- 話題の作成や返信などの操作が簡単
- スマホからの操作がしやすい
など、wiki上での議論に有用な機能が充実していた。そのため、議論が比較的多くなされる上記の3つのwikiに導入してみた。
Structured Discussionsは、ページや名前空間ごとに有効化する必要がある。ある特定のページにおいてこの拡張機能を有効化したい場合は、特別ページ「Special:EnableStructuredDiscussions」(特別:Structured Discussions の有効化)を使う。しかし、この特別ページを使用し、「トーク」または「利用者・トーク」以外の名前空間にあるページ*1においてStructured Discussionsを有効化しようとすると、詳細不明のエラー*2が発生してページの移行作業が中断されてしまった。その場合、対象ページのStructured Discussionボード*3化と既存のページの過去ログ化は行われるが、変換後のボードの説明欄や過去ログページにテンプレートが追加されず、過去ログページが孤立してしまうという問題が起こる。テンプレートを手作業で追加することはできるが、正しくテンプレートを書くことは煩雑な作業なので、できれば避けたい。
一方、ある名前空間のすべてのページにおいてStructured Discussionsを有効化する場合は、後述する移行作業を行った後、LocalSettings.php 内で以下のように名前空間のコンテンツ・モデルを設定するだけでよい。
<?php $wgNamespaceContentModels[NS_TALK] = 'flow-board'; $wgNamespaceContentModels[NS_USER_TALK] = 'flow-board';
対象の名前空間にある既存のページは、メンテナンススクリプト extensions/Flow/maintenance/convertNamespaceFromWikitext.php を使用して一括移行することができる。以下のように実行すれば、名前空間「トーク」や「利用者・トーク」にあるページは問題なく移行することができた。
# MW_INSTALL_PATH: MediaWikiがインストールされている場所 cd $MW_INSTALL_PATH/extensions/Flow/maintenance sudo -u Webサーバーを動かしているユーザー php convertNamespaceFromWikitext.php --server='srw.wiki.cre.jp' Talk sudo -u Webサーバーを動かしているユーザー php convertNamespaceFromWikitext.php --server='srw.wiki.cre.jp' User_talk
また、このメンテナンススクリプトを使用した場合、移行作業の途中でエラーが発生したとしても、スタックトレースが表示されるため原因を調べやすい。
そこで、単一のページに対してこのメンテナンススクリプトが提供する移行機能を使えるようにすれば、対象のページの移行が成功しやすくなり、エラー発生時にも対処しやすくなるのではないかと考えた。そのため、単一ページを対象として移行作業を行うメンテナンススクリプトを作ることにした。
単一ページを対象として移行作業を行うメンテナンススクリプト
今回作ったメンテナンススクリプトのコードを以下に示す。convertNamespaceFromWikitext.php を改造してこのスクリプトを作った。
これを convertPageToSDBoard.php という名前でMediaWikiをインストールしたディレクトリに保存した後、以下のように実行する。sudo でWebサーバーを動かしているユーザーとして実行することは、一時ファイルを作る権限を得るために必要だった。
# MW_INSTALL_PATH: MediaWikiがインストールされている場所 cd $MW_INSTALL_PATH/extensions/Flow/maintenance sudo -u Webサーバーを動かしているユーザー php convertPageToSDBoard.php 移行するページの名前
処理手順は、「Special:EnableStructuredDiscussions」における入力から対象ページ名を取得する処理を行った後、そのページを対象として convertNamespaceFromWikitext.php の移行処理を行う、という単純なもの。ただし、対象ページが名前空間「トーク」または「利用者・トーク」に存在しなければならないという制限をなくしている。エラーが発生した場合は、例外処理においてロガーがスタックトレースを表示するため、原因を調べやすい。
実行結果
名前空間「トーク」、「利用者・トーク」にあるページに加えて、それ以外の名前空間にあるページも上記のメンテナンススクリプトで問題なくStructured Discussionボードに移行することができた。処理内容自体は「Special:EnableStructuredDiscussions」と大して変わらないため、特別ページでエラーが発生してしまう理由は分からなかった。
まとめ
指定した単一のページをStructured Discussionsボードに移行するメンテナンススクリプトを作った。このメンテナンススクリプトを使うことで、単一のページのStructured Discussionsボードへの移行が成功しやすくなり、エラーが発生した場合もスタックトレースから原因を特定しやすくなる。複数のページに対して使う機会があれば、より効率よく移行作業が行える。
*1:スパロボWikiやTYPE-MOON Wikiでは、「Project」名前空間にあるページ「BBS/2019」などが掲示板として使用されている。それらのページにおいて、Structured Discussionsが提供する掲示板機能を使いたかった。
*2:データベースのロールバックが発生していたので、データベースの更新に失敗していたようだったが、どの段階でエラーが発生したのかは表示されなかった。PhabricatorのT197234が関連していると思われる。
*3:ボードとは、Structured Discussionの掲示板機能が有効化されたページのこと。詳細はmediawiki.orgの「Help:Structured Discussions/Glossary/ja」を参照。
SICP:問題2.17
とても久しぶりにSICPの問題をやってみた。前回の問題から飛んでいるけど(一応間の問題も解いてはある)、今回初めて使ってみたGaucheの単体テストでの確認が便利だったので、思わず先に書いてしまった。
問題 2.17
与えられた(空でない)リストの最後の要素だけからなるリストを返す手続き
last-pairを定義せよ:(last-pair (list 23 72 149 34)) (34)
length と同じようにリスト全体の cdr ダウンで。Schemeの組み込みライブラリに同名の手続きが入っているので、my-last-pair という名前にした。
(define (my-last-pair items) (if (null? (cdr items)) items (my-last-pair (cdr items))))
gauche.testを使ったテスト
ところで、今まではテストを手でやっていたのだけど、試すときに使っていたGaucheに単体テストのライブラリgauche.testが含まれていることを知り、今回初めて使ってみた。
上の手続きをex-2-17.scmというファイルに入れ、以下の内容のex-2-17-test.scmというファイルを作った。
;; 問題2.17のテスト (use gauche.test) (test-start "問題2.17") (load "./ex-2-17.scm") (test "要素数1の場合" (list 1) (lambda () (my-last-pair (list 1)))) (test "問題文の例" (list 34) (lambda () (my-last-pair (list 23 72 149 34)))) (test-end :exit-on-failure #t)
実行すると以下のように出力され、テストが成功したことが分かる。
$ gosh ex-2-17-test.scm Testing 問題2.17 ... test 要素数1の場合, expects (1) ==> ok test 問題文の例, expects (34) ==> ok passed.
テストが失敗するように、わざと以下のテストケースを入れるとどうなるか。
(test "絶対失敗する!" (list 23) (lambda () (my-last-pair (list 23 72 149 34))))
出力はこのようになり、失敗した場合の結果が分かりやすく表示された。
$ gosh ex-2-17-test.scm Testing 問題2.17 ... test 要素数1の場合, expects (1) ==> ok test 問題文の例, expects (34) ==> ok test 絶対失敗する!, expects (23) ==> ERROR: GOT (34) failed. discrepancies found. Errors are: test 絶対失敗する!: expects (23) => got (34)
かなり便利なので、今後答えがはっきりと決まる問題を解くときには、積極的に使っていきたい。
MroongaをTravis CIのVM上のUbuntu 14.04で動作させる
今年の9月に入ったあたりから、全文検索用のMySQLストレージエンジンMroongaを使っているRailsアプリ*1のTravis CIでのテストが、エラーにより実行できなくなった。ログを調べてみると、Travis CIのVM上で動作しているUbuntu 14.04へのMroongaのインストールに失敗し、そこで止まっていたことが分かった。
その後なかなか時間が取れず放置していたが、先日試行錯誤したところ、Mroongaのインストールに成功し、テストを実行できるようになった。今回はその際の修正方法をまとめてみる。
原因
原因は、Travis CIのVM上のUbuntu 14.04に標準でインストールされているMySQLと、MroongaのUbuntu 14.04用のパッケージが要求するMySQLのバージョンが異なることだった。前者は5.6系で、後者は5.5系となっていた。
ログ(例:Job #416.4 - cre-ne-jp/log-archiver - Travis CI)の該当部分は以下のようになっていた。
Build system information
(中略)
mysql version
mysql Ver 14.14 Distrib 5.6.33, for debian-linux-gnu (x86_64) using EditLine wrapper
(中略)
$ sudo apt-get install -y -V mysql-server-mroonga
Reading package lists... Done
Building dependency tree
Reading state information... Done
Some packages could not be installed. This may mean that you have
requested an impossible situation or if you are using the unstable
distribution that some required packages have not yet been created
or been moved out of Incoming.
The following information may help to resolve the situation:
The following packages have unmet dependencies:
mysql-server-mroonga : Depends: mysql-server-5.5-mroonga (= 7.06-2~trusty1) but it is not going to be installed
Depends: mysql-server (= 5.5.57-0ubuntu0.14.04.1) but it is not going to be installed
E: Unable to correct problems, you have held broken packages.
対策
対策として、標準でインストールされているMySQL 5.6をアンインストールし、Mroongaのパッケージが要求するMySQL 5.5をインストールできるようにすることが浮かんだ。問題発生前はVM上でMySQL 5.5のインストールされているUbuntu 12.04が動作していて、mroonga-server-5.5-mroonga パッケージが問題なくインストールできていた。
Mroongaのインストール手順
以下では.travis.ymlの before_install: 欄に書く内容を示す。
まず、Mroonga公式のUbuntu向けインストール方法の説明にしたがって、パッケージのインストールのための準備を行う。
universeリポジトリとセキュリティアップデートリポジトリを有効にする。
sudo apt-get install -y -V software-properties-common lsb-release sudo add-apt-repository -y universe sudo add-apt-repository "deb http://security.ubuntu.com/ubuntu $(lsb_release --short --codename)-security main restricted"
ppa:groonga/ppa PPAをシステムに追加する。
sudo add-apt-repository -y ppa:groonga/ppa sudo apt-get update
通常は以上の準備の後 mysql-server-mroonga パッケージをインストールするが、ここでMySQL 5.6関連のパッケージをアンインストールする。アンインストール手順については、Benjamin Morel氏のGist「Install MySQL 5.7 on Travis-CI」を参考にした。
sudo apt-get remove --purge "^mysql.*"
sudo apt-get autoremove
sudo apt-get autoclean
sudo rm -rf /var/{lib,log}/mysql
これでMySQL 5.6関連のパッケージとデータがすべて除かれるので、MySQL 5.5系がベースになっている mysql-server-mroonga パッケージをインストールすることができる。
sudo apt-get install -y -V mysql-server-mroonga
ただ、このパッケージだけでは開発用のヘッダファイルがインストールされず、後に mysql2 gemのインストールで失敗してしまう。そのため libmysqlclient-dev を忘れずにインストールしておく。念のため、上記のパッケージの後でインストールするようにし、互換性のあるバージョンが確実に選ばれるようにした。
sudo apt-get install -y -V libmysqlclient-dev
ここまでの手順はシェルスクリプトにまとめておいた。
テスト用のMySQLアカウントの変更
Travis CIのVMに標準でインストールされているMySQLでは travis ユーザーが使えるように設定されているので、テスト時はそのユーザーを使うようにアプリ側で設定されているかもしれない。新しく入れたMySQLではそのような設定はされていないので、以降のテストでデータベースに接続できなくなる可能性がある。
そこで、テスト時に travis ユーザーを使うように設定している場合は、そのユーザーを用意するか、使わないようにする。今回はとりあえず root にパスワードなしで接続するように設定を変えたが、セキュリティ面ではよくないかもしれない。
Mroongaのインストール成功
以上の対策を行った結果、Mroongaのインストールに成功し、テストが無事実行できるようになった。
例:Job #434.4 - cre-ne-jp/log-archiver - Travis CI
まとめ
Travis CIのVM上のUbuntu 14.04では、Mroongaのインストールに失敗してテストが停止してしまう。その原因は、標準でインストールされているMySQLとMroongaのUbuntu 14.04用のパッケージが要求するMySQLのバージョンが異なることだった。
標準でインストールされているMySQL 5.6関連のパッケージをアンインストールした後でMroongaをインストールするという対策により、問題を解決することができた。
*1:irc.cre.jp系IRCサーバ群で使われているIRCログ記録・閲覧システム「log-archiver」
研究分野への興味の喪失
夏休みに入り、興味を持ったソーシャルデータの分析の研究室の先生とお会いしてお話を伺った。その後、提出しなければならない修士課程の研究計画書を書くために調査をしていたが、調べているうちに興味がなくなってきた。
先生との面談の際には、ここ何年かの実習で災害についての情報を扱う機会が何回かあったこともあり、ソーシャルメディアへの投稿から災害についての情報を検出し、物理センサを補完するような仕組みを作りたいと伝えた。特にこの時期に多く起こる豪雨災害を対象にしようと考えていた。そのまま話が進んだので、研究計画書を書くためにさらに調査を進めたが、調べていくと成功する見込みが少ないと感じられるようになった。
例えば代表的なソーシャルデータであるツイートを収集するボットを作るのは今からすぐにできると思う。作っていたIRCボットのcre-ne-jp/rgrbでTwitter gemを使っている経験があるから、APIについて調べて利用し、得られたデータを整形すれば良いだろう。自然言語処理を利用した必要なデータの抽出も、頑張って勉強しながらなんとかできるようになりそうだとは思った。その後の他データとの比較は、時刻や位置情報に注目しながら地道にやっていくことになるだろう。
問題はテーマに当てはまる投稿がそもそもあるのかどうか。調べていくうちに、これが心配になってきた。
最近の関連研究はほとんどない。東日本大震災の直後は結構多いように見えたが、最近は下火になっているようだった。これは興味を持っている人が少ないか、やってみたが成果がほとんどないということを示しているように感じられた。
それなりに上手くいっていそうな例は、早稲田大の「人間科学研究」に載っていた、服部による「位置情報付きツィートから事象 (自然現象・異常気象)・災害を可視化する手法の開発」だけだった。ただ、修士論文の要旨なので詳細は分からなかった。
他に、災害情報No. 14(2016)に掲載された潮崎・牛山による「豪雨時における災害危険度の高まりを推定するための電話通報数の活用について」の参考文献に載っていた、影澤らによる「Twitterを用いたセンシングシステムの提案と考察」(「マルチメディア、分散協調とモバイルシンポジウム2014論文集」に掲載)が気になったが、人が多い新宿でも降雨初期のツイートが数件というのを見て愕然とした。一応降雨を検出できたことになっているが、1時間に少なくとも数千件のツイートを収集しているのに対象ツイートがこの件数になるというのでは、多少のシステムの改良ではどうしようもないほど関連するツイートの絶対数が少ないということではないだろうか。
さらに同じ日に読んだ2015年関東・東北豪雨災害土木学会・地盤工学会合同調査団関東グループによる調査報告書を読んでより悲観的になった。p. 135の「避難情報の入手手段」の図の「SNS(Twitter、LINE、Facebook等)」の割合が0.4%(N = 516)というのは、要するに、そんな大災害のときに呑気にSNSに興じているような人はほとんどいないことを示していると思われた。一応「入手手段」なので投稿数もそれくらい少ないとは限らないが、平時に近い上の新宿の場合と比べれば、非常時には普通は減るだろう。また、別の豪雨災害の2014年広島豪雨は深夜に酷い被害が出たことから、そのような場合もSNSへの投稿はほぼなくなるだろうと推測した。
というわけで、ここ数日集中して調べた限りでは、豪雨災害を研究対象とすると投稿のサンプルが集められずに挫折する可能性が高いという予想になった。そのため、自分はこのテーマに賭けようという気持ちになれなかった。
他には研究室の本流らしい観光に関連したデータの抽出が流行っているようだったが、利用者に合わせた推薦の手法の提案ばかりで、差別化が難しいと感じた。あまり興味が持てなかったこともあり、今は独自のテーマが浮かびそうにない。
当初は個々の技術がおもしろそうだと思っていたが、適用できそうな範囲の狭さを知り、ソーシャルデータの分析への興味がなくなってきた。代わりの案はまだ浮かんでいない。
gstreamermmでGStreamerのチュートリアル1
卒研で使うThe Imaging Source社の産業用カメラをLinuxで制御する1ためにマルチメディアフレームワークのGStreamerを使うことになりそうなので、その練習をしている。
卒研ではOpenCVと組み合わせる予定なので、C++で書けると扱いやすい。GStreamerはC言語で書かれたライブラリだが、C++ラッパーのgstreamermmが用意されているので、これを使うことにした。
GStreamer公式の説明ページにはチュートリアルがいくつか用意されている。今回は最初のチュートリアル1を、gstreamermmを使って書いてみた。
開発環境
ライブラリのインストール
Homebrewを使って必要なライブラリをインストールした。
サンプル動画を再生するために、libvpxおよびlibvorbisとのリンクが必要。また brew link --force gettext が必要になる。これを行わないと、書いたプログラムのリンクの際に「libintlが見つからない」というエラーが出た。後に問題が発生したら brew unlink gettext を行う必要があるかもしれない。
brew install pkg-config gstreamer gst-plugins-good gettext brew install gst-plugins-base --with-libogg --with-libvorbis brew install gst-plugins-bad --with-libpng --with-libvpx brew link --force gettext
ソースコード
CMakeLists.txt
「CMake 簡易まとめ」を参考にした。
cmake_minimum_required(VERSION 3.0) project(tutorial CXX) find_package(PkgConfig) pkg_check_modules(GSTREAMERMM REQUIRED gstreamermm-1.0) set(CMAKE_CXX_FLAGS "-std=c++11 -Wall") set(CMAKE_CXX_FLAGS_DEBUG "-g3 -O0 -pg") set(CMAKE_CXX_FLAGS_RELEASE "-O2 -s -DNDEBUG -march=native") set(CMAKE_CXX_FLAGS_RELWITHDEBINFO "-g3 -Og -pg") set(CMAKE_CXX_FLAGS_MINSIZEREL "-Os -s DNDEBUG -march=native") add_executable(tutorial01 tutorial01.cpp) target_include_directories(tutorial01 PUBLIC ${GSTREAMERMM_INCLUDE_DIRS}) target_link_libraries(tutorial01 ${GSTREAMERMM_LIBRARIES}) target_compile_options(tutorial01 PUBLIC ${GSTREAMERMM_CFLAGS_OTHER})
tutorial01.cpp
チュートリアルのコードをgstreamermmを使って書き直した。
#include <gstreamermm-1.0/gstreamermm.h> int main(int argc, char* argv[]) { // GStreamerを初期化する Gst::init(argc, argv); // パイプラインを構築する Glib::RefPtr<Gst::Element> pipeline = Gst::Parse::launch( "playbin uri=https://www.freedesktop.org/software/gstreamer-sdk/data/media/sintel_trailer-480p.webm" ); // 再生を開始する pipeline->set_state(Gst::STATE_PLAYING); { // エラーまたはEOSまで待つ Glib::RefPtr<Gst::Bus> bus = pipeline->get_bus(); Glib::RefPtr<Gst::Message> msg = bus->pop( Gst::CLOCK_TIME_NONE, Gst::MESSAGE_ERROR | Gst::MESSAGE_EOS ); } // リソースを解放する pipeline->set_state(Gst::STATE_NULL); return 0; }
C言語で書かれたチュートリアルのコードは以下のとおり。
#include <gst/gst.h> int main(int argc, char *argv[]) { GstElement *pipeline; GstBus *bus; GstMessage *msg; /* Initialize GStreamer */ gst_init (&argc, &argv); /* Build the pipeline */ pipeline = gst_parse_launch ("playbin uri=https://www.freedesktop.org/software/gstreamer-sdk/data/media/sintel_trailer-480p.webm", NULL); /* Start playing */ gst_element_set_state (pipeline, GST_STATE_PLAYING); /* Wait until error or EOS */ bus = gst_element_get_bus (pipeline); msg = gst_bus_timed_pop_filtered (bus, GST_CLOCK_TIME_NONE, GST_MESSAGE_ERROR | GST_MESSAGE_EOS); /* Free resources */ if (msg != NULL) gst_message_unref (msg); gst_object_unref (bus); gst_element_set_state (pipeline, GST_STATE_NULL); gst_object_unref (pipeline); return 0; }
ビルド
CMakeの慣習に従い、buildディレクトリを作ってその中でビルドする。
cd /path/to/tutorial01 mkdir build cd build cmake .. make
実行
ビルドしたら以下のコマンドで実行することができる。
./tutorial01
実行するとウィンドウが表示され、https://www.freedesktop.org/software/gstreamer-sdk/data/media/sintel_trailer-480p.webm の再生が始まる。最後まで再生されると終了する。

C言語で書かれたものとの違い
生ポインタの代わりにGlib::RefPtrを使う
例えば GstElement * 型が返る関数のgstreamermm版では Glib::RefPtr<Gst::Element> が返る。
Glib::RefPtr(リファレンス)はglibmmが提供する参照カウンタ式のスマートポインタクラスで、C++11のstd::shared_ptrに似ている。デストラクタでカウントが1減り、0になったときにリソースが解放される。このスマートポインタのおかげで、gst_object_unref() に相当する ->unreference() を呼び出さなくてもよくなる。
上のコードではポインタを使用する範囲をブロックにした。ブロックを抜ける際にデストラクタが呼ばれ、C言語版とほぼ同じ場所で ->unreference() が呼ばれることになる。
一部の関数のインターフェースが異なる
多くの関数のgstreamermm版はC言語版からの規則的な変換で書けるが、一部インターフェースが異なるものがある。上の例だと、gst_bus_timed_pop_filtered() に対応する関数は Gst::Bus::pop(Gst::ClockTime timeout, Gst::MessageType message_type) と、オーバーロードを利用したものになっている。
一つ一つドキュメントから探していけば良いのだが、インターネットでは現在の最新版1.8.0のドキュメントのページが空になっているため、少し不便になっている。gstreamermmをHomebrewでインストールした場合は /usr/local/opt/gstreamermm/share/doc/gstreamermm-1.0/reference/html/index.html からDoxygenで生成されたドキュメントを見ることができた。未確認だが、Linuxではlibgstreamermm-1.0-docのようなパッケージをインストールすれば閲覧できそうだ。
感想
常にリソース管理に注意しなければならないC++なので、スマートポインタでリソースの解放し忘れが減ることが嬉しい。慣れていないのでまだドキュメントを何度も見ているが、もともとGStreamerがオブジェクト指向で書かれているので、対応するgstreamermmの関数を見つけるのは難しくなかった。個人的にはC++11以降の書き方が気に入っていて、できるだけC++で書きたいと思うので、今後も積極的にgstreamermmを使っていきたい。
-
制御するためのLinux用ライブラリがGitHubで公開されている:
https://github.com/TheImagingSource/tiscamera↩
2016-11-18 の日記
「標準課題」というグループ課題で、友達の班に「C言語でメールを送れるようにしたい」という要望があった。おもしろそうだったので、放課後に実験を一緒にやってみた。
構成
学校にはファイアウォールがあってインターネット上のSMTPサーバに直接アクセスすることができないようだったので、とりあえず課題用に配られたRaspberry PiをSMTP・POP3/IMAPサーバとすることにした。Raspberry Piにユーザーアカウントを作り、Maildirにメールが届くようにする。
前提
ユーザーアカウントは事前に作ってあり、ログインできるものとする。なければ useradd -m someone で作っておく。
Postfixのインストールと設定
Raspbian Jessieを使っていたので、Debian 8での設定手順がそのまま使える。「Debian 8 Jessie : MAILサーバー : Postfix インストール/設定 : Server World」を参考にした。実験用で外に出すつもりがなかったし、時間の余裕があまりなかったので、以下の点は変えた。
- インストール中、構成のプリセットの選択で「ローカルのみ」を選んだ。
- 容量制限やSMTP-Authの設定をしなかった。
SMTPサーバの確認
初めにmailutilsを入れてmailコマンドを使えるようにした。
sudo apt-get install mailutils
また、RaspbianではMAIL環境変数が設定されていなかったようなので、以下の内容で /etc/profile.d/mail.sh を作ってログイン時に設定されるようにした。
export MAIL=$HOME/Maildir
反映させるため、一旦ログアウトして再度ログインする。
続いてsendmailコマンドで自分宛てにメールを送った。
sendmail ocha@example.org # 以下は標準入力 From: ocha@example.org To: ocha@example.org Subject: Hello Hello world! .
送信後、mailコマンドで確認すると、送ったメールが届いていた。
C言語でメールを送るプログラムを作る
sendmailコマンドを呼び出して標準入力に書き込めばメールを送信できたので、popen(3)でそれを行う。エラー対策等は厳密ではないので注意。
/* * send-hello.c */ #include <stdio.h> int main(int argc, char* argv[]) { if (argc != 3) { fprintf(stderr, "Usage: %s NAME ADDRESS\n", argv[0]); return 1; } char* name = argv[1]; char* address = argv[2]; char sendmail_command[256]; snprintf(sendmail_command, sizeof(sendmail_command), "sendmail %s", address); FILE* sendmail = popen(sendmail_command, "w"); if (sendmail == NULL) { perror("popen"); return 1; } fputs("From: ocha@example.org\n", sendmail); fprintf(sendmail, "To: %s\n", address); fputs("Subject: Hello\n\n", sendmail); fprintf(sendmail, "Hello, %s!\n", name); fputs(".\n", sendmail); pclose(sendmail); return 0; }
使うときはこのような形で。
./send-hello ocha ocha@example.org
Dovecotのインストールと設定
最後にPOP3/IMAPサーバとしてDovecotをインストールして、メールソフトから受信したメールを見られるようにした。Postfixと同様に「Debian 8 Jessie : MAILサーバー : Dovecot インストール/設定 : Server World」を参考にした。
PCのThunderbirdでIMAPサーバとしてRaspberry PiのIPアドレスとポート番号143を指定して、上のプログラムを使って送信したメールを受信できることを確認した。
感想
調べながら作業を行ったので時間がかかったが、要点を押さえればそれほど複雑ではない印象だった。
sendmailコマンドはなかなか便利。ちょうど学校でプロセス関連のシステムコールやライブラリ関数の使い方を習った後だったので、良い応用例だった。Raspberry Piなら、ハードウェアの制御と合わせればおもしろいものができそう。
HHVMのコンパイルエラー対策
スーパーロボット大戦Wiki等のMediaWikiを動かすためのHHVMを3.14.2に更新しようとしたときに、まずCMakeで失敗した。これはサブモジュールを再帰的にすべてダウンロードできていなかったためで、以下のコマンドを実行することで次に進めた。
# gitでcloneしたHHVMのディレクトリで rm -rf third-party git submodule update --init --recursive
しかし、その後makeするとコンパイルエラーが起きて止まってしまった。コンパイルに失敗するのは hphp/hack/src/server/serverError.ml で、探してみたところ以下のissueが見つかった。
新しいバージョンではだめなのかと3.14.1等バージョンを戻して試してみるもどうもうまくいかない。さらに探してみると、以下のissueが見つかり、そこに衝撃の事実が。
jwatzman commented on 31 Dec 2015
ocaml's build systems are terrible when it comes to incremental builds. Can you try
rm -rf hphp/hack/src/_buildand try again?「Error: Unbound value ServerMonitor.start_monitoring · Issue #6701 · facebook/hhvm」より
訳すと「OCamlのビルドシステムはインクリメンタルビルドになるとひどい。rm -rf hphp/hack/src/_build をやってもう一度試してもらえる?」といったところか。こんな罠は知らなかった…
というわけで、上記のとおりにできたファイルを削除してもう一度ビルドをかけたらすんなり進んだ。しかし3コアのVPSではビルドにかなり時間がかかるようで、2時間弱も待つことに。